AI writes the code. Who governs the quality? (Sponsored)
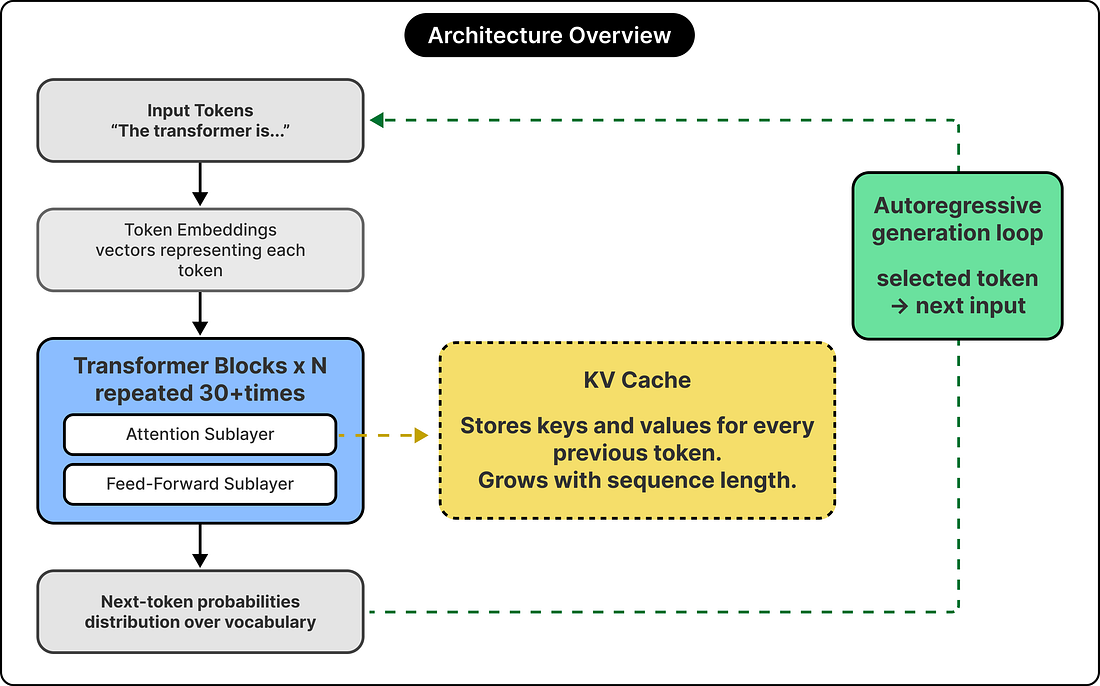
AI-assisted development has changed how code gets written, but for many teams, testing and governance haven’t caught up. Tricentis AI Workspace closes that gap, giving quality engineering leaders one place to build, orchestrate, and govern AI quality agents across the SDLC, from code risk analysis and test automation to performance validation so quality decisions happen continuously, not at the end. Less errors introduced by AI-generated code, more confidence in what you’re shipping. Discover how teams are using AI Workspace to bring structure to AI-driven development and compress delivery timelines without sacrificing confidence in business outcomes. Apple’s most ambitious AI feature runs in about a gigabyte of memory on the iPhone. The same company runs a much larger model on its own cloud servers, and the two diverge in almost every architectural choice beyond the word “transformer” in their lineage. The same split shows up at Google, Microsoft, and Meta, where one family of small models targets devices and a different family of large models targets data centers. Small and large language models are different engineering responses to different constraints, and the differences begin with where each model runs, what hardware it targets, and how it was trained. In this article, we will explore those constraints through three layers of model design, look at the tradeoffs that come with each approach, and investigate the production systems that combine both small and large models. Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies. FoundationsBefore we look at what makes the two classes different, it helps to be precise about what makes them the same. Both small and large language models are transformer-based decoder models, built by stacking layers of the same basic computational block. Each block runs an attention operation, which figures out which previous tokens matter most for predicting the next one, followed by a feed-forward computation that mixes that information through a wide intermediate layer. The model repeats this block thirty or more times before producing a probability distribution over what the next token should be.
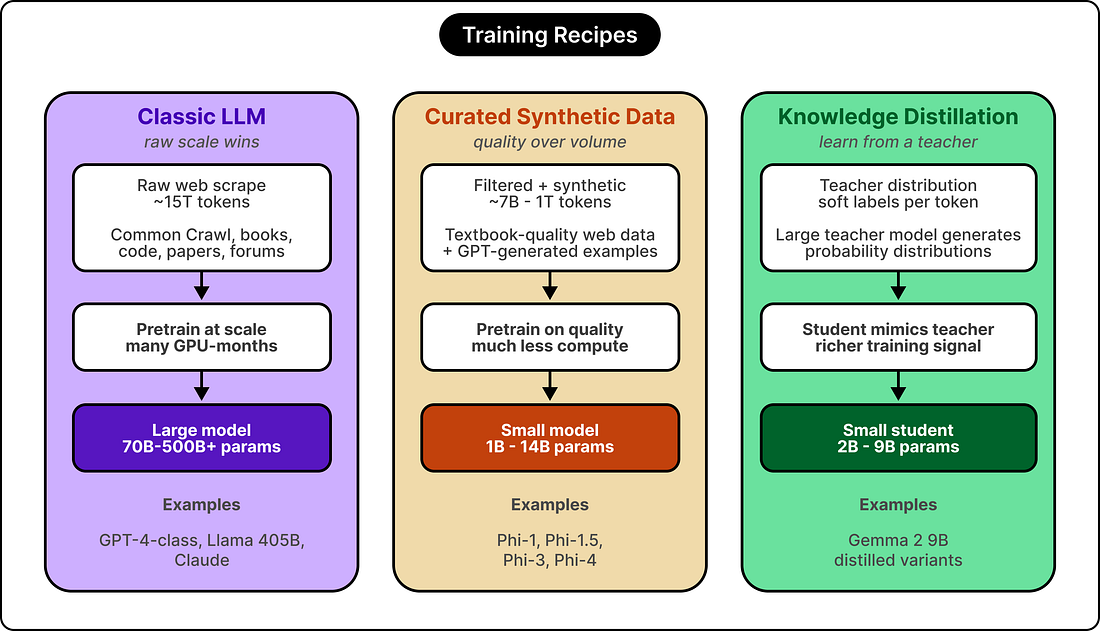
Both classes go through similar training stages. They start with pretraining on large text corpora, where the model learns to predict the next token across billions of examples. They typically follow with supervised fine-tuning on specific instruction patterns, and many go through reinforcement learning from human feedback, which shapes how the model handles ambiguity and stays helpful in conversation. The size of a model refers to its number of parameters, which are the learned weights adjusted during training. A small model in 2026 typically has between half a billion and fourteen billion parameters. A large model has tens of billions to hundreds of billions of parameters, and sometimes more. ConstraintsThree constraints pull the designs of small and large models in opposite directions.
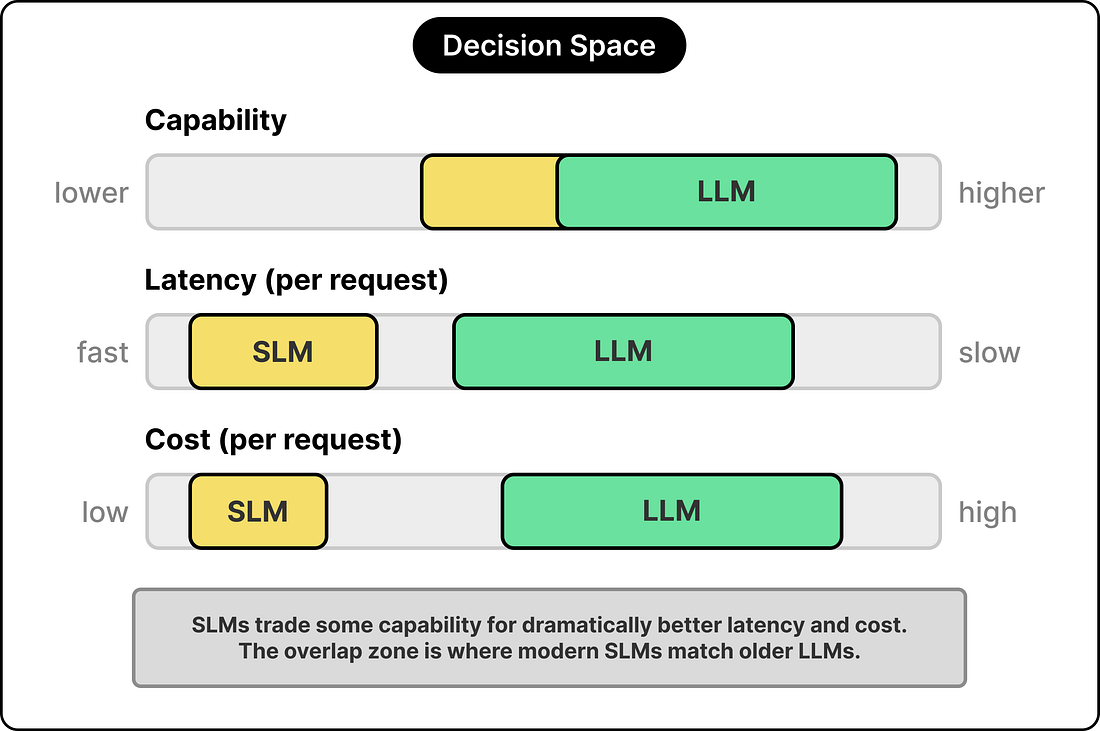
The deployment target determines everything that follows. A model that runs on a phone has a memory budget measured in single gigabytes, a battery budget measured in milliamps, and a latency budget measured in milliseconds. A model that runs in a data center operates in a more permissive environment, with concerns around throughput, batching efficiency, and cost per request, but with an absolute resource ceiling orders of magnitude higher. Inference economics is the second pressure. Training a model is a one-time cost paid at the start of its life, while serving the model is a recurring cost paid every time someone uses it. For a high-volume product, the inference bill quickly dwarfs the training bill, so a team designing for high inference volume will gladly spend more training compute upfront to save inference compute across billions of requests downstream. The training budget is the third pressure. A frontier large model can cost tens of millions of dollars to train, while most teams working on small models operate with a small fraction of that, and the smaller budget forces choices. Those teams have to find other levers beyond raw scale, which usually means smarter training data, distillation from larger teachers, and more efficient training recipes. These three constraints reinforce each other rather than acting in isolation. A model designed for the phone has a small inference budget per request and usually a smaller training budget too, while a model designed for the data center has the opposite profile across all three axes. The result is two distinct design regions in the same space.
Who’s actually reviewing all that AI-generated code? (Sponsored)
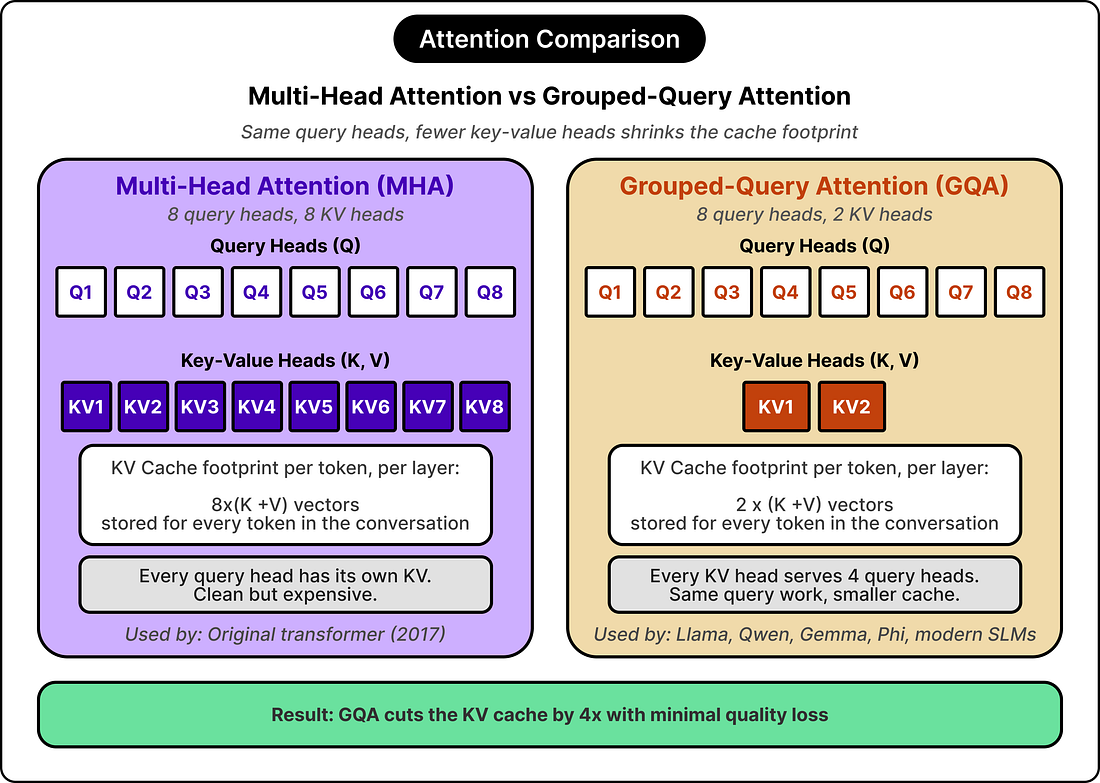
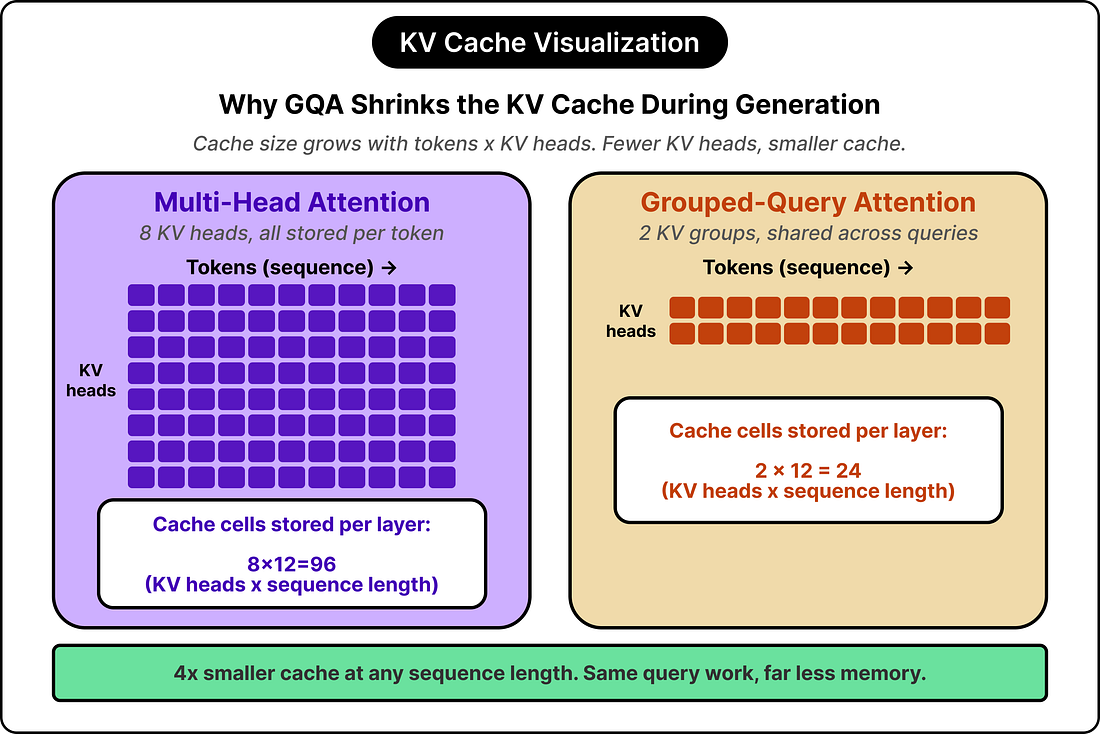
When devs use AI to generate thousands of lines of unverified code, you risk a codebase slopocalypse. The review step becomes your team’s bottleneck, and the last thing standing between a subtle bug and production. Greptile reviews each PR with full repo context and learns your team’s conventions over time from comments, reactions, and what gets merged. It flags real issues and suggests fixes that match your team, not generic best practices. ✅ Recently launched TREX runs your code, not just reads it. Greptile executes the change in a sandbox and returns screenshots, logs, and traces as proof of what actually broke. ✅ Review from your terminal. The Greptile CLI runs the same review locally, before you ever open a PR. ✅ Trusted by engineering teams at NVIDIA, Scale AI, and Brex. ✅ Now integrated with Claude Code: install via /plugin. ✅ Free for open source. ArchitectureThe architecture differences begin with a quick observation about inference. During generation, the model has to keep around the keys and values for every previous token, since attention works by comparing the current token against all earlier ones. This stored set is called the KV cache, and it grows linearly with the length of the conversation. For long generations, the cache often dominates memory bandwidth and storage, more than the parameters themselves. This single fact decides how small-model architectures get designed. In the original transformer design, every attention head has its own keys and values, an arrangement called multi-head attention. For long sequences, the resulting cache footprint grows large enough to dominate the model’s memory consumption. Grouped-query attention attacks the problem directly. The number of query heads stays the same, but several queries share a single key-value pair. A model with thirty-two query heads might use only eight key-value groups, which cuts the cache footprint by a factor of four with minimal quality loss. Llama, Qwen, Gemma, and most modern small models use grouped-query attention by default, and many large models have adopted it as well because the math also helps at scale. Some small models push further. Gemma 2 interleaves sliding window attention with full attention across layers, so some layers attend only to the most recent few thousand tokens rather than the full context. This trades a bit of long-range reasoning for a significantly smaller cache. Apple’s on-device model shares its KV cache across multiple decoder layers, reusing the same stored state in several places.
These architectural decisions all serve the same goal of shrinking the runtime cost of inference, which is the constraint that matters most when the model has to run on a device with a few gigabytes of memory to spare. TrainingTwo models with identical architectures can end up with very different capabilities depending on what they were trained on and how. Three techniques define the current state of the art in small-model training:
The first technique is data curation. In 2023, a Microsoft research team published a paper called “Textbooks Are All You Need.” They trained a 1.3 billion parameter coding model on roughly seven billion tokens of carefully filtered code and synthetically generated textbook-style data. The model matched or beat models trained on hundreds of billions of tokens of raw web scrape. Training data quality could substitute for training data volume, at least for certain capabilities. The Phi family kept building on that insight, and the modern Phi-4 model continues to lean heavily on synthetic data quality as its primary lever. The second technique is knowledge distillation. The small model, called the student, learns from a larger model, called the teacher, by mimicking the teacher’s output distribution rather than only learning from raw text. The richer training signal helps the student pick up patterns it would struggle to learn from the underlying corpus alone. Gemma 2 used this approach to train its nine billion parameter model, while training its twenty-seven billion parameter version from scratch. The third technique is overtraining relative to compute-optimal. In 2022, the Chinchilla paper from DeepMind established that for a fixed compute budget, the best model came from balancing parameter count and training data, roughly twenty tokens of training data per parameter. Modern small models deliberately train on far more data than that ratio suggests. A three-billion-parameter model might see many trillions of tokens during training, which is many times the Chinchilla-optimal amount. Once the model gets deployed, every percentage point of quality improvement saves inference compute across billions of requests, so the team spends more on training to save more on serving.
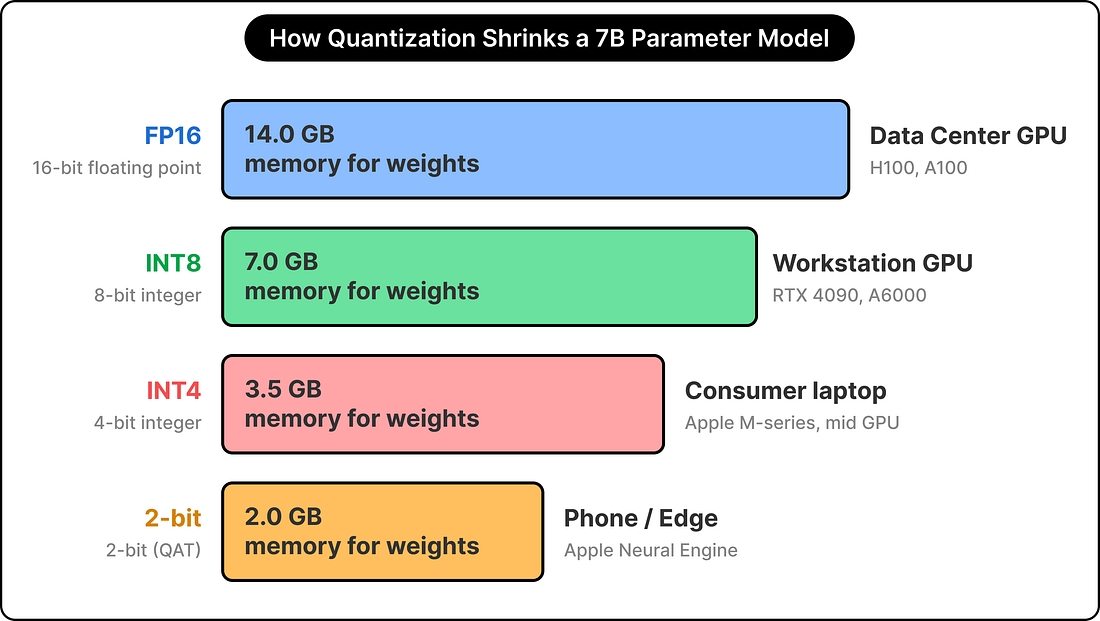
DeploymentThe final layer of design choices covers how the model executes on real hardware. The two dominant techniques are quantization, which shrinks the storage cost of each parameter, and KV cache management, which shrinks the runtime cost of generation. Quantization is the practice of storing each parameter with fewer bits. A standard pretrained model stores each parameter as a sixteen-bit floating point number, where cutting that to eight bits halves the memory footprint and cutting to four bits halves it again. The post-training approach is faster to implement but tends to lose quality at aggressive bit widths, while quantization-aware training preserves quality at the cost of more complex training.
Hardware mapping is the next consideration. Apple’s Neural Engine has different strengths from an NVIDIA Jetson, which has different strengths from a data center H100, and the model design follows the target hardware. Phi-4-mini gets tuned for consumer GPUs. Gemma 3 4B variants run on NVIDIA Jetson Orin for edge AI deployments in robotics and embedded systems. Apple’s 3B model runs on the iPhone’s Neural Engine with the assumption that the device also handles other workloads at the same time. KV cache management is the second major lever, and it connects directly back to the architecture section. The cache stores keys and values for every previous token during generation, and its size determines how much memory the model utilizes at runtime. Grouped-query attention attacks this by reducing the number of key-value heads, and Apple’s on-device model goes further by sharing its cache across multiple decoder layers.
These deployment decisions stack on top of everything earlier. The same architectural choices that shrink the KV cache also make quantization easier, and the same training recipes that produce capable small models also produce models that survive aggressive compression. TradeoffsSmall models perform well on standard benchmarks like MMLU and HumanEval. Production usage looks more varied. Three gaps tend to matter most:
The first gap is generalization. Small models tend to be more brittle outside their training distribution, and they can be excellent at tasks similar to what they saw during training, while showing weakness on unexpected ones. A small model trained heavily on code performs well on code but may struggle with creative writing in an unusual style. A model trained on synthetic textbook data does well on textbook-style questions but can falter on the messy, ambiguous prompts that real users send. The second gap is multi-step reasoning. For problems that require chaining inference across many tokens, large models still have a noticeable advantage. The gap has been closing thanks to step-by-step reasoning techniques and reasoning-focused fine-tuning, but at very small parameter counts, the ceiling remains real. Phi-4 has done well on math reasoning specifically because Microsoft optimized for that capability through training data design, while a general-purpose small model usually shows a clearer gap. The third gap is world knowledge. Parameters function as a form of memory, and a larger model can store more facts, more named entities, more obscure references, and more multilingual coverage. A small model has a fundamental cap on how much it can know, since storage requires parameters and parameters require memory. For applications that need broad factual recall, the small model often pairs with an external knowledge source that the model queries when needed, since trying to fit all that knowledge into the parameters themselves would push the model past its budget. HybridsThe most interesting design question in 2026 is rarely which model to use. The more useful question is how to compose multiple models into a system that uses each for what it does best. Three patterns appear in most production setups.
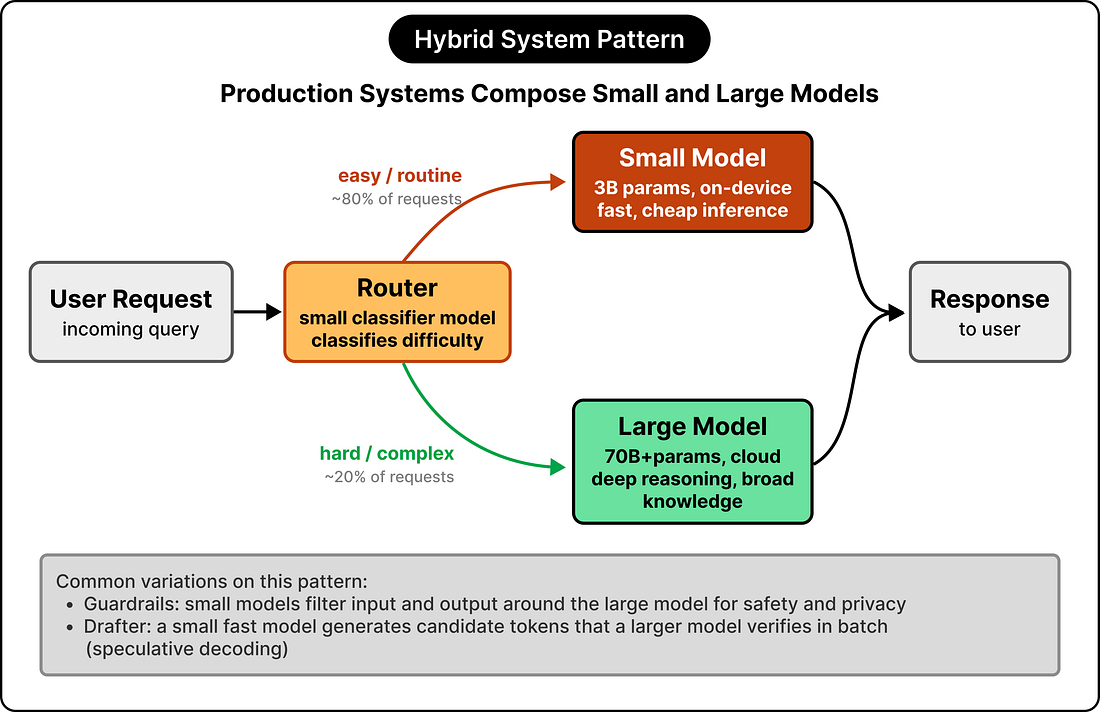
The most common pattern is routing. A small model handles the request directly if it falls within its competence, and escalates to a large model when the request is harder than it can confidently handle. The pattern resembles caching tiers in a distributed system, where the fast, cheap layer handles the common case, and the slower, more expensive layer handles the rest. The router itself is often a small classifier model that decides which path to take. The second pattern is the guardrail. A small model sits in front of the large model to filter or classify input before the expensive computation runs, checking for unsafe content, classifying the intent of the request, or stripping out information that should stay private. A second small model often sits on the output side, doing similar checks before the response gets returned to the user. These guardrail models are cheap, fast, and specialized, which makes them well-suited to the role. The third pattern is the drafter, sometimes called speculative decoding. A small fast model generates candidate tokens, and a larger, more capable model verifies them in batch. When the verifications agree, the system gets the throughput of the small model with the quality of the large one. Apple’s on-device system uses a draft model alongside its base model for exactly this reason. The technique sounds like a hack, but it has become standard in production inference systems. Picking a model class is the wrong frame for most product decisions. Designing a system around multiple model classes is the right frame, and the interesting design work lives in the composition layer, the routing logic, the fallback behavior, and the orchestration between models.
ConclusionThe question we started with was “small versus large language models,” and the more useful version of that question turns out to be “which constraints drove each model’s design.” The size of a model is a downstream consequence of those constraints rather than the starting point for the design. Three layers of design choices flow from the constraints:
Small models are extremely capable for their size, and they have a real ceiling on generalization, on multi-step reasoning, and on broad world knowledge. Production systems handle this by composing both classes, using small models for the common case and large models for the harder requests, sometimes with multiple small models acting as routers, guardrails, and drafters around a larger core. For a working engineer choosing between models, the right starting point is the constraints rather than the benchmark. The questions that matter are about deployment target, inference budget, and the shape of the request distribution in production. References:
|

#6636 WWE 2K26 v1.06 + 6 DLCs [Monkey Repack] Genres/Tags: Arcade, Fighting, Sports, 3D Companies: 2K Games, Visual Concepts Languages: ENG/MULTI6 Original Size: 129.2 GB Repack Size: 107.8 GB Download Mirrors (Direct Links) .dlinks {margi… Read on blog or Reader FitGirl Repacks Read on blog or Reader WWE 2K26, v1.06 + 6 DLCs [Monkey Repack] By FitGirl on 28/03/2026 # 66 3 6 WWE 2K2 6 v1.0 6 + 6 DLCs [Monkey ...
Comments
Post a Comment