The Robot Vacuum Making Intelligent Automation Possible at Home (Sponsored)
Matic is the first visually intelligent robot vacuum that sees your home like you do, so it can clean how you want it to.
Experience autonomous cleaning with Matic with a 180-day money-back guarantee. OpenAI runs voice AI for 900 million users a week, and they use WebRTC for it because the alternative would mean reinventing how the internet handles live audio. The catch is that WebRTC was designed for servers with stable IPs and ports, and Kubernetes treats those addresses as disposable. The conventional answer at this scale is an SFU, which suits multiparty workloads like group video calls, but OpenAI’s traffic is overwhelmingly one user talking to one model. To deal with this, their architecture splits the stack into two pieces:
The trick that ties them together is using the ICE ufrag, a field the protocol already exchanges during setup, as a routing key that the relay can read off the first packet of a new session. Everything else, from Global Relay to the userspace Go implementation to the Redis cache and the careful socket-level optimizations, builds on top of that core idea. In this article, we will look at the entire journey in detail and challenges the OpenAI engineering team faced. Disclaimer: This post is based on publicly shared details from the Open AI Engineering Team. Please comment if you notice any inaccuracies. Why Latency Matters For Voice AIVoice AI either feels like a conversation or it feels like a walkie-talkie. The line between those experiences is measured in milliseconds. When the network pauses between hearing a user and responding, the illusion breaks. Pauses turn awkward, interruptions get clipped, and users are compelled to cut off the AI mid-sentence, which is also kind of rude. In other words, voice AI only feels natural if the conversation moves at the speed of speech. The harder constraint underneath is the continuous-stream property. Audio has to arrive at the model as a steady flow, rather than as a single upload after the user finishes talking. That stream is what lets the model start transcribing, reasoning, and calling tools while the user is still speaking. The experience collapses into push-to-talk once it breaks. For OpenAI specifically, those constraints translate into three concrete requirements:
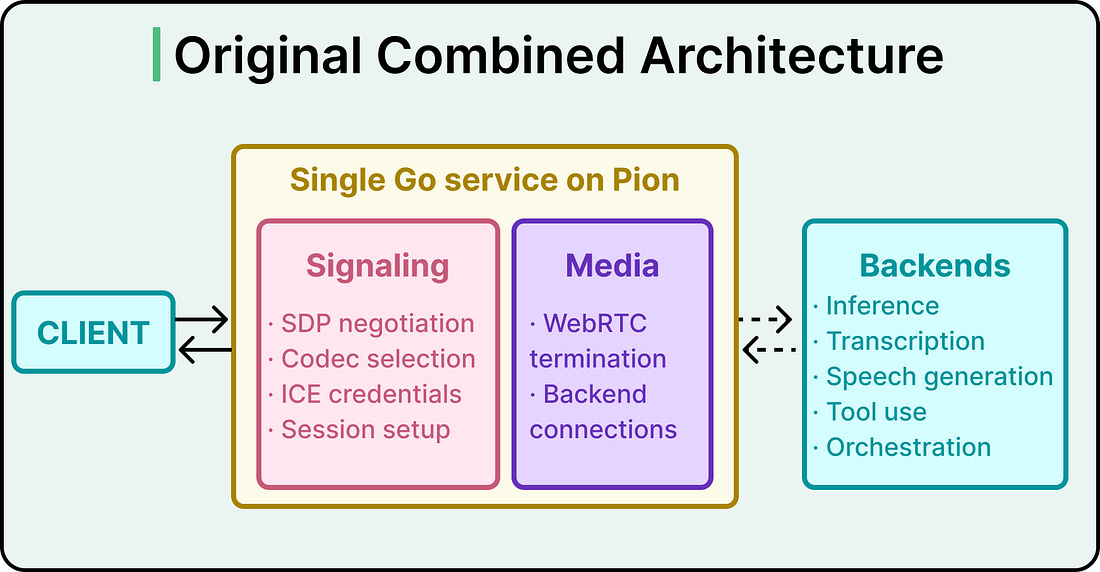
WebRTC is the protocol the industry built for this kind of work. It is a bundle of smaller protocols (ICE for figuring out how two endpoints reach each other across firewalls, DTLS for encrypting the channel, SRTP for the audio packets, and RTCP for quality feedback). Justin Uberti, one of WebRTC’s original architects, and Sean DuBois, who maintains the Pion library OpenAI builds on, both work at OpenAI today. That kind of protocol depth shows up in the architecture they shipped. The Original ArchitectureThe first version of OpenAI’s WebRTC infrastructure was a single Go service built on Pion. It handled both jobs in one place:
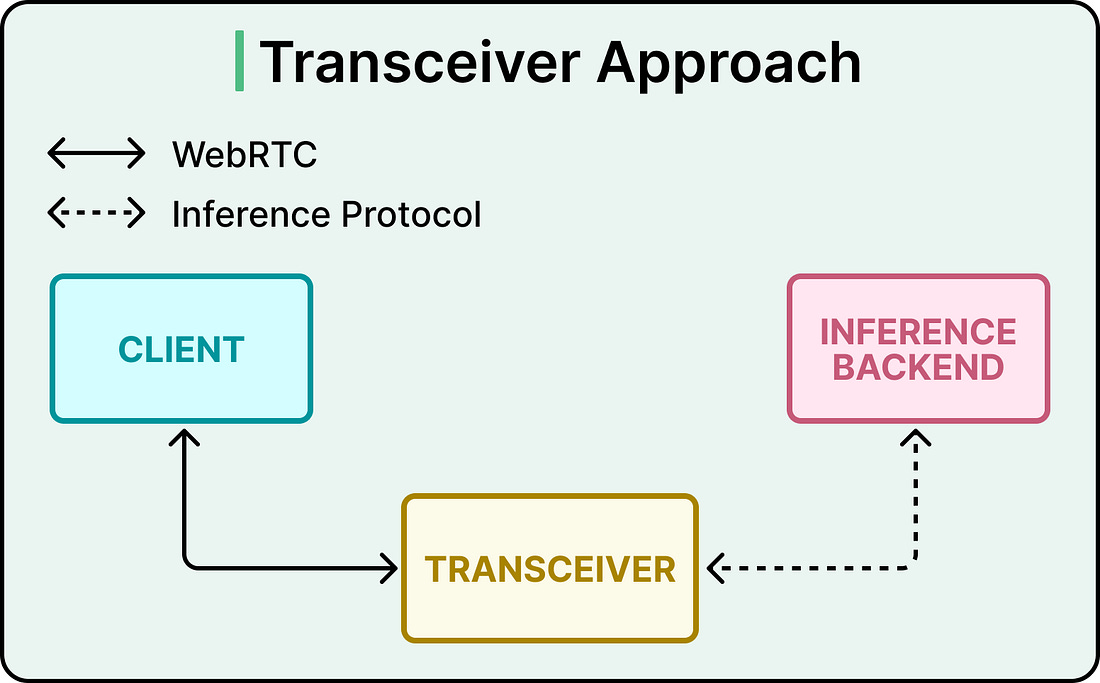
That combined service still powers ChatGPT voice, the Realtime API’s WebRTC endpoint, and several research projects, and it has handled that work well. The question OpenAI ran into was how to deploy it on Kubernetes, the container orchestration system that runs most modern cloud infrastructure. Kubernetes assumes compute is cheap and movable. Pods come up, get scheduled wherever capacity exists, run for a while, then get rescheduled or replaced. Standard WebRTC deployment patterns assume the opposite. That mismatch shows up in two specific places. The first is port exhaustion. The conventional way to deploy WebRTC uses one UDP port per session. At OpenAI’s scale, that means tens of thousands of public UDP ports per service. Cloud load balancers were built for a handful of well-known ports, so each additional range adds operational complexity for load balancer config, health checks, firewall policy, and rollout safety. The exposed surface area also makes security audits harder. Kubernetes autoscaling clashes with the requirement to reserve large and stable port ranges, which makes elasticity brittle. The second is state stickiness. Running one UDP port per server and demultiplexing sessions behind it solves the port problem. ICE and DTLS, however, are stateful protocols. The process that started a session has to keep receiving its packets to validate connectivity checks, complete the DTLS handshake, decrypt SRTP, and process later session changes like ICE restarts. If a packet for an existing session lands on a different process, setup fails, or media breaks. Both pressures point to the same answer. The deployment architecture has to change while the client experience stays identical. Splitting The Relay From The TransceiverThe architecture OpenAI shipped splits packet routing from protocol termination. A stateless relay sits at the front, presenting a small public footprint to the internet. A stateful transceiver sits behind it, owning all the heavy WebRTC state. Signaling still goes directly to the transceiver. Media enters through the relay first. The relay’s scope is deliberately narrow. It reads enough of each packet to choose a destination, then forwards the rest as an opaque payload. Audio stays encrypted on the way through, ICE state machines stay with the transceiver, and codec negotiation happens elsewhere. From a client’s perspective, the WebRTC session looks normal in every way. The transceiver owns the parts of WebRTC that have to remember things. ICE connectivity checks, the DTLS handshake, SRTP encryption keys, and the session lifecycle all live there. The transceiver is the endpoint that completes the handshakes and encrypts or decrypts the actual media. See the diagram below:
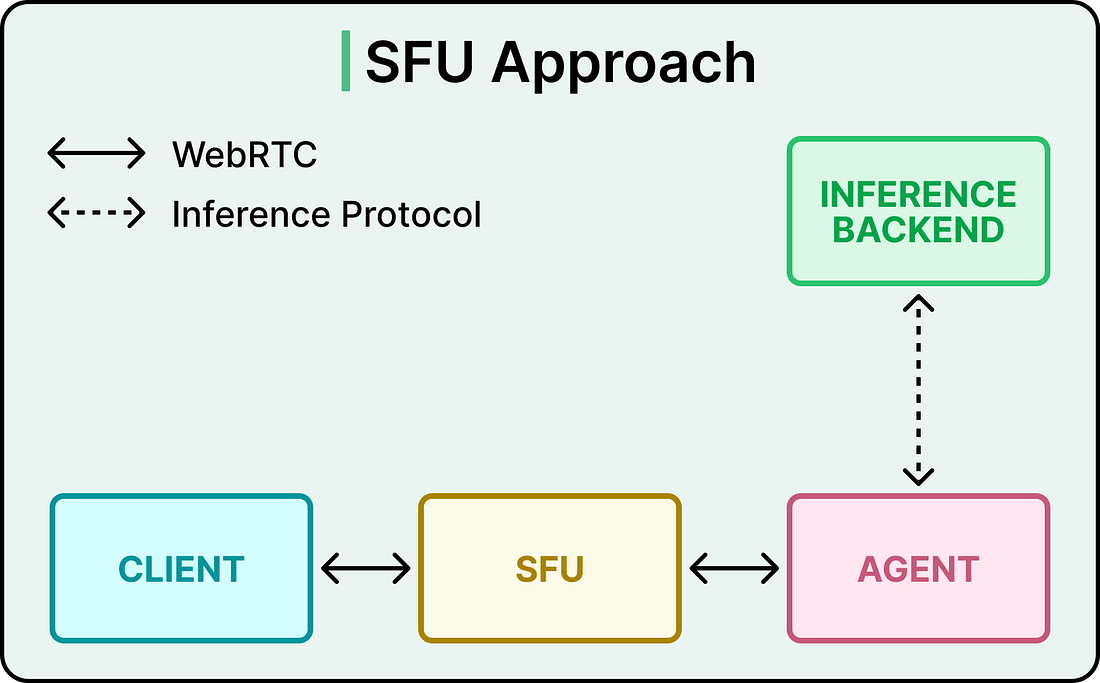
There was an obvious alternative that the team evaluated and chose against. An SFU, or Selective Forwarding Unit, is the standard media server architecture for WebRTC at scale. It terminates one WebRTC connection per participant and selectively forwards streams between them. The AI joins as another participant. This works well for inherently multiparty products like group calls, classrooms, and collaborative meetings. OpenAI’s workload looks different. Most sessions are 1:1, with one user talking to one model. For that kind of traffic, the SFU model adds overhead and forces backend services to behave like WebRTC peers themselves. The transceiver model lets the backend stay an ordinary service. See the diagram below that shows the SFU approach:
TURN was also considered and set aside. TURN is the standard protocol-terminating relay used for NAT traversal. The trouble is that TURN allocations add setup round-trips before media can flow, and migrating or recovering them across servers is hard. For a latency-sensitive workload, those extra round-trip matters. The split solves the port and state problems in principle. The remaining problem is making the relay route the first packet correctly. Routing The First PacketThe first packet of any new session is the difficult one. Subsequent packets are easy because the relay has a mapping that says that packets from this source IP and port go to this transceiver. The first packet is what creates that mapping, so the relay has to figure out where to send it from the packet itself. See the diagram below:
Two naive options were present:
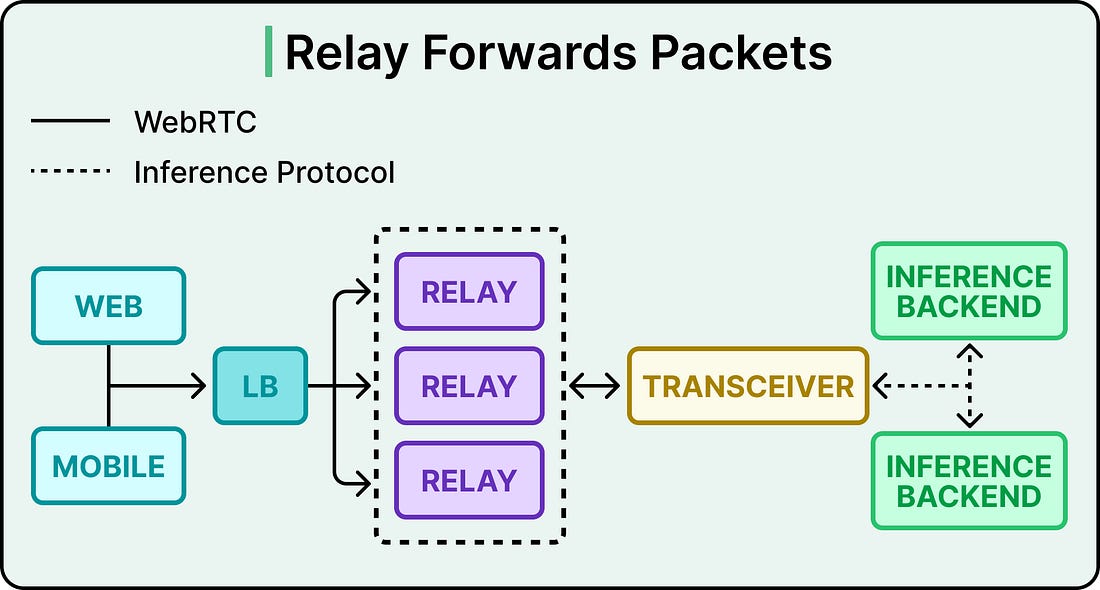
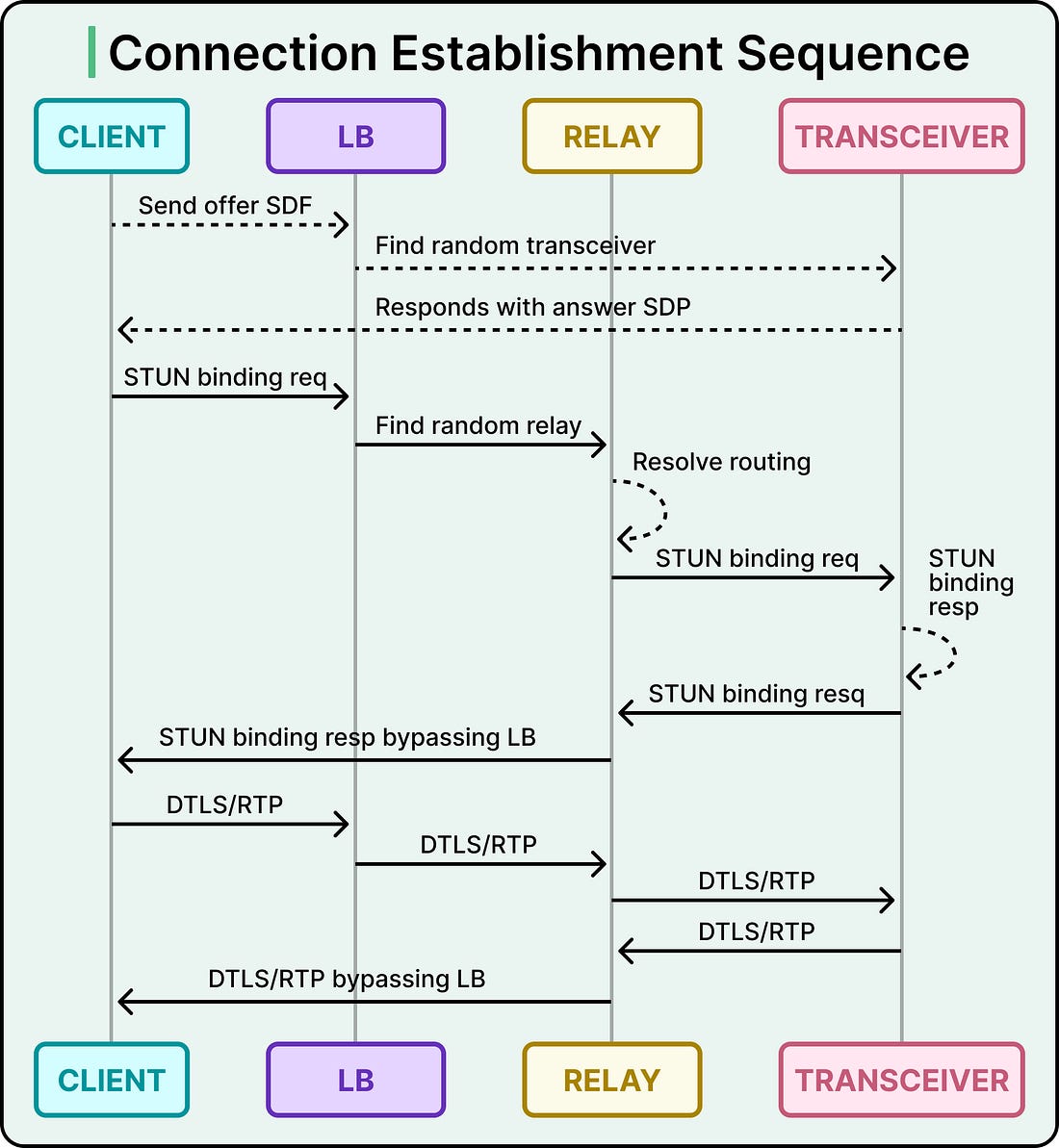
OpenAI chose a third option. The answer lives inside a field that WebRTC already exchanges. Every WebRTC session carries an ICE username fragment, called the ufrag, which is produced during session setup and echoed in STUN binding requests. STUN binding requests are the packets ICE uses to verify that two endpoints can actually reach each other, and they are usually the first thing a client sends on the media path. The trick is that OpenAI generates the server-side ufrag during signaling. They can put whatever they want in it, so they encode routing metadata into it. The relay parses just enough of the first STUN binding request to read the ufrag, decode the routing hint, and forward the packet to the transceiver that owns the session. Every packet after the first one flows through the established session mapping, which skips the ufrag parsing step entirely. See the diagram below that shows the connection establishment sequence in detail:
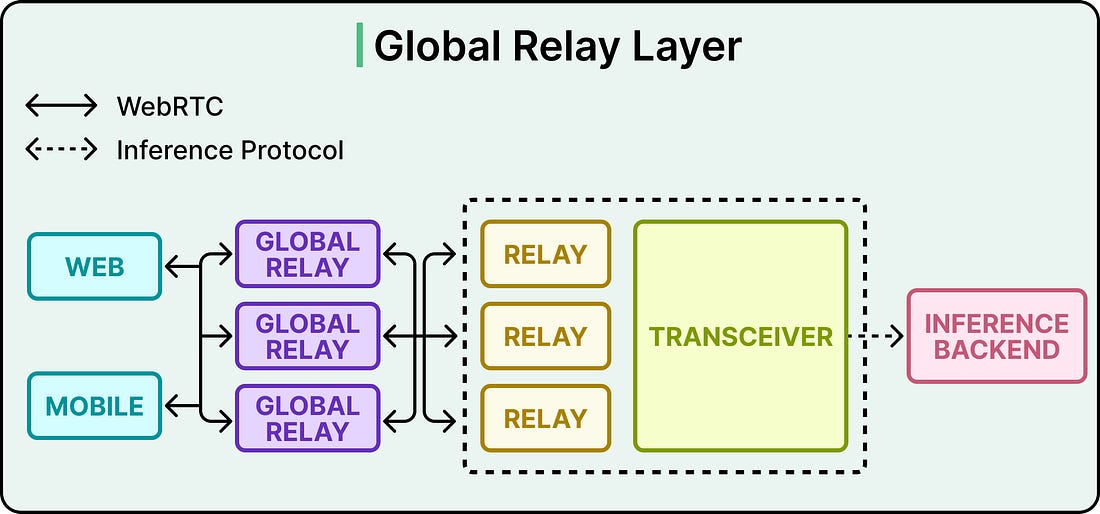
Each transceiver in the fleet listens on a shared UDP socket, which is one operating system endpoint bound to an internal IP and port. All sessions for that transceiver multiplex behind it. During signaling, the transceiver returns a shared relay VIP and UDP port in the SDP answer. A VIP is a virtual IP address that fronts the entire relay fleet, so the client sees one stable destination like 203.0.113.10:3478, even though many relay instances sit behind that address. From the client’s side, there is one place to send packets, and it stays the same for the life of the session. The relay’s state is purposefully tiny. It holds an in-memory map of source address to transceiver destination, plus some counters for monitoring and timers for session cleanup. If a relay instance restarts and loses the mapping, the next STUN packet rebuilds it from the ufrag. To make recovery faster, a Redis cache holds the source-to-destination mapping once a route is established. A restarted relay can look up the mapping from Redis immediately. The principle here generalizes well. When we need data on the hot path, look at what the protocol is already exchanging. A field on the payload is essentially free to parse. A new lookup costs latency, a dependency, and one more thing that can break. Global Relay and Geo-Steered SignalingOnce the public UDP surface was reduced to a small fixed set of addresses, the same relay pattern became deployable globally. Global Relay is OpenAI’s fleet of geographically distributed relay ingress points. All of them run the identical packet-forwarding behavior described above. The only thing that changes is where on the map they sit.
Geographic distribution shortens the first client-to-OpenAI hop. A packet entering the network at a relay close to the user, in both geography and network topology, has a much easier time than a packet that has to traverse the public internet to reach a distant region first. The practical effect is lower latency, more stable timing, and a cleaner loss profile before traffic reaches the OpenAI backbone. OpenAI uses Cloudflare for geographic and proximity steering on the signaling side. The initial HTTP or WebSocket request that sets up a session is routed to a nearby transceiver cluster. The request context then determines which Global Relay ingress point gets advertised back to the client in the SDP answer. The ufrag carries enough information for Global Relay to route media to the right cluster, and for the cluster’s relay to route to the right transceiver. The result is that both the signaling and the media paths enter the OpenAI network at points close to the user, while the session itself stays anchored to one specific transceiver for its full lifetime. The setup round-trip and the first ICE connectivity check both shorten, which directly reduces how long a user waits before they can start speaking. The Go Relay ImplementationThe relay is a Go service running in userspace, which is to say a regular process that reads from a regular UDP socket. The Linux kernel receives UDP packets from the network interface, delivers them to a socket bound to the relay’s IP and port, and the Go process reads from that socket, updates a small amount of flow state, and forwards each packet to the right transceiver. OpenAI evaluated kernel-bypass frameworks (which let a userspace process poll the network card’s queues directly) and chose to stay away. Bypass raises packet throughput at the cost of operational complexity. The team’s workload fit inside what a careful Go implementation could handle. Three implementation choices carry most of the performance load.
The takeaway is that ordinary optimizations were enough. The relay handles OpenAI’s global real-time media traffic on a relatively small footprint. Design TradeoffsEvery architecture comes with tradeoffs, and this one carries several worth understanding.
ConclusionThe architecture OpenAI built for voice AI is a careful response to a specific pressure. WebRTC was designed for stable servers. Modern cloud infrastructure runs on the opposite assumption. OpenAI’s team had the protocol depth to determine whether a WebRTC session needs to live in one process at all. Their answer separates the work into two pieces. A stateless relay forwards packets near the user. A stateful transceiver, anchored in one place, owns ICE, DTLS, SRTP, and the session lifecycle. The two pieces communicate through information that’s already in the WebRTC handshake, which keeps the routing decision on the packet path itself. The implementation choices stayed deliberately simple. Userspace Go, SO_REUSEPORT, thread pinning, and careful memory management did the work that kernel bypass solves. The result handles 900 million weekly users on a relatively small relay footprint. References:
|

#6636 WWE 2K26 v1.06 + 6 DLCs [Monkey Repack] Genres/Tags: Arcade, Fighting, Sports, 3D Companies: 2K Games, Visual Concepts Languages: ENG/MULTI6 Original Size: 129.2 GB Repack Size: 107.8 GB Download Mirrors (Direct Links) .dlinks {margi… Read on blog or Reader FitGirl Repacks Read on blog or Reader WWE 2K26, v1.06 + 6 DLCs [Monkey Repack] By FitGirl on 28/03/2026 # 66 3 6 WWE 2K2 6 v1.0 6 + 6 DLCs [Monkey ...
Comments
Post a Comment