✂️ Cut your QA cycles down to minutes with QA Wolf (Sponsored)
If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf. QA Wolf’s AI-native service supports web and mobiles apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes. QA Wolf takes testing off your plate. They can get you:
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production. With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles. Large Language Models like GPT-4 and Claude have transformed the way we interact with computers. However, despite their incredible utility in general scenarios, they face fundamental limitations that prevent them from being immediately useful in many business contexts. Some of these limitations are as follows:
Retrieval-Augmented Generation or RAG solves these problems by giving AI systems access to specific documents and data. Instead of relying solely on what the model learned during training, RAG allows the system to look up relevant information from a particular document collection before generating a response. Think of it as providing the AI with a reference library it can consult whenever it needs to answer a question. Help us Make ByteByteGo Newsletter BetterTL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo CodeRabbit: Free AI Code Reviews in CLI (Sponsored)
CodeRabbit CLI is an AI code review tool that runs directly in your terminal. It provides intelligent code analysis, catches issues early, and integrates seamlessly with AI coding agents like Claude Code, Codex CLI, Cursor CLI, and Gemini to ensure your code is production-ready before it ships.
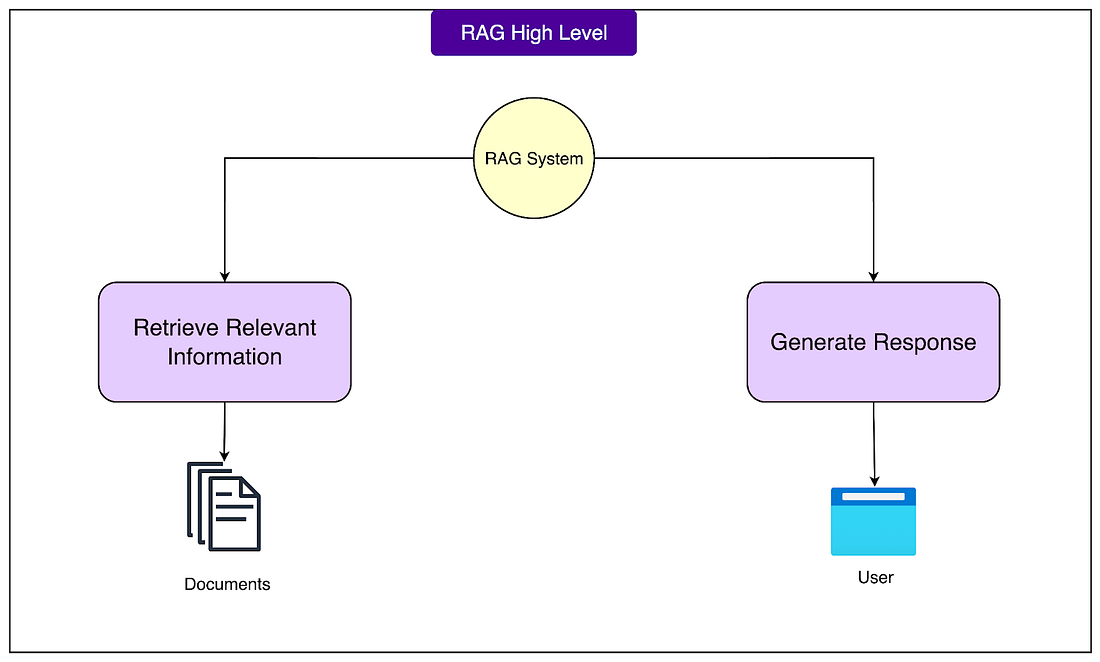
What is RAG?At its core, Retrieval-Augmented Generation is a technique that combines two different processes into one system:
The name itself tells the story. We retrieve relevant documents first, then augment the generation process with that retrieved context. Imagine walking into a library and asking the librarian a specific question about the local tax code. A regular librarian might share general knowledge about taxes, but a librarian with access to the city's specific tax documents could walk to the right shelf, pull out the relevant manual, read the specific section, and give an exact answer based on those official documents. This is what RAG does. The difference between RAG and asking an LLM directly is significant. When we ask a standard LLM about a company's vacation policy, it might respond with generic information about typical vacation policies it learned during training. It might say something like "Many companies offer two to three weeks of paid vacation" because that's a common pattern it may have seen. With RAG, the system first retrieves the actual employee handbook, finds the section about vacation policy, and then generates a response based on that specific document. The answer would be "According to the employee handbook, full-time employees receive 15 days of paid vacation in their first year, increasing to 20 days after three years of service." See the diagram below for a high-level view of how RAG works:
Understanding when we need RAG and when a standard LLM is sufficient is an important factor in making good architectural decisions. Some of the cases when RAG is more useful are as follows:
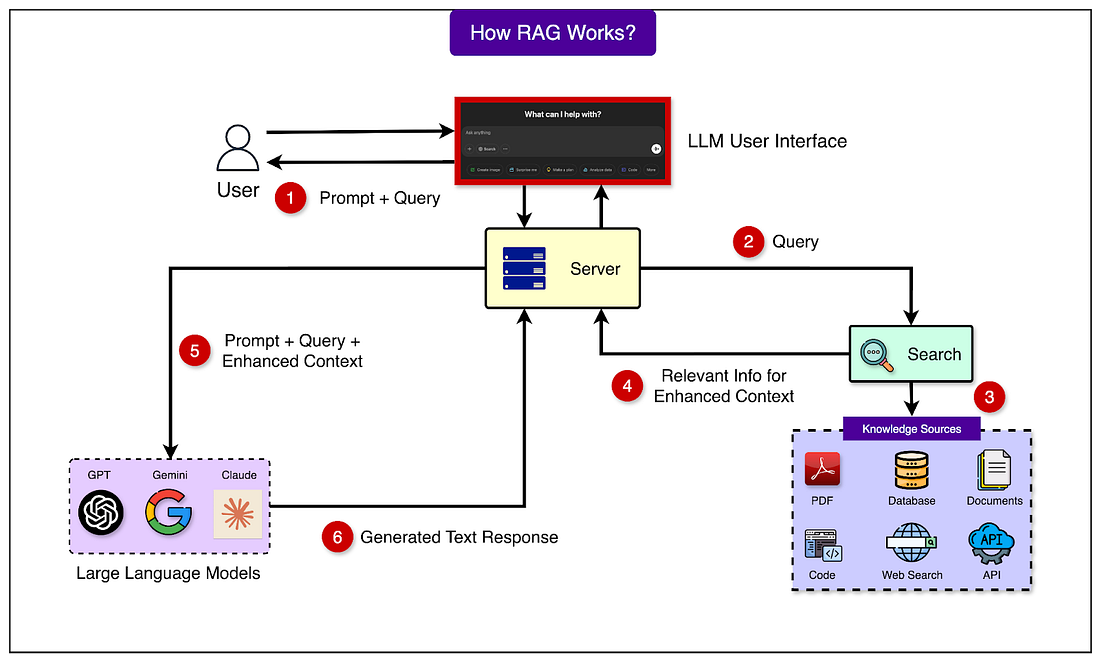
On the other hand, we don't need RAG for general knowledge questions that the LLM can already handle quite well, like explaining common concepts, performing basic reasoning, or creative writing tasks. How RAG Works - The Journey of a QueryThis journey involves two distinct phases that happen at different times:
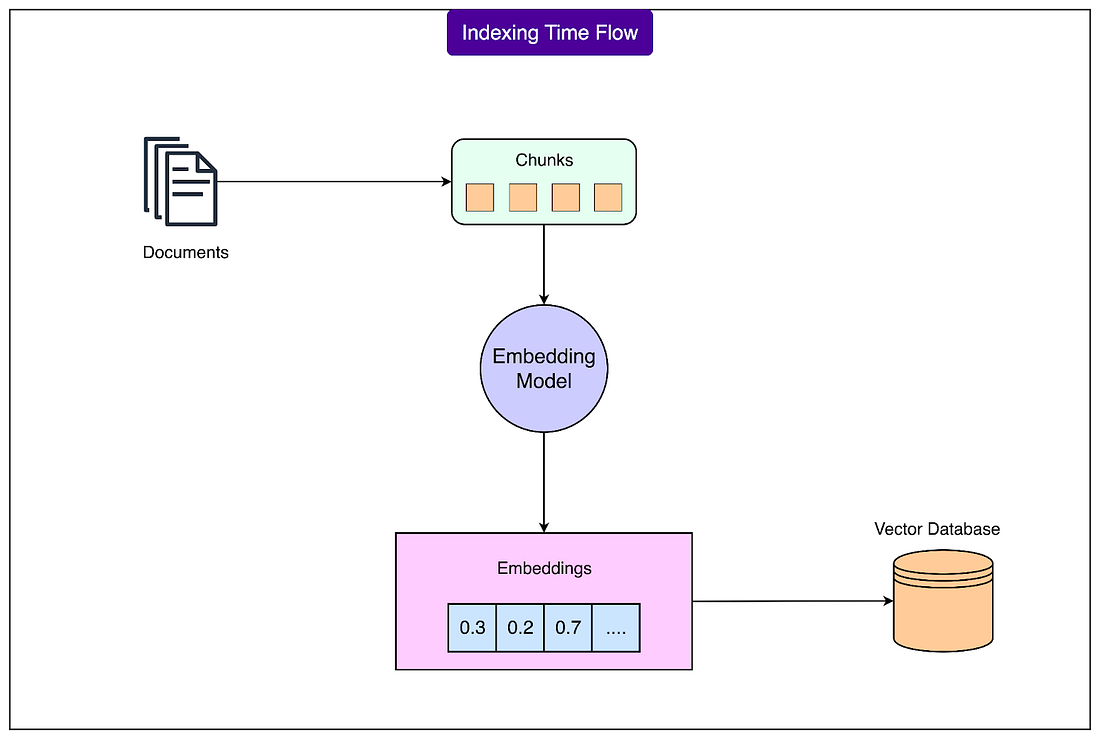
This two-phase approach is powerful because of the separation of concerns it provides between the computationally intensive document-preparation phase and the latency-sensitive query phase. Let’s look at both phases in more detail: 1 - PreparationThe document preparation phase is like organizing a library before it opens. This foundational work happens before any user queries arrive and involves several crucial steps. See the diagram below:
The overall process works as follows:
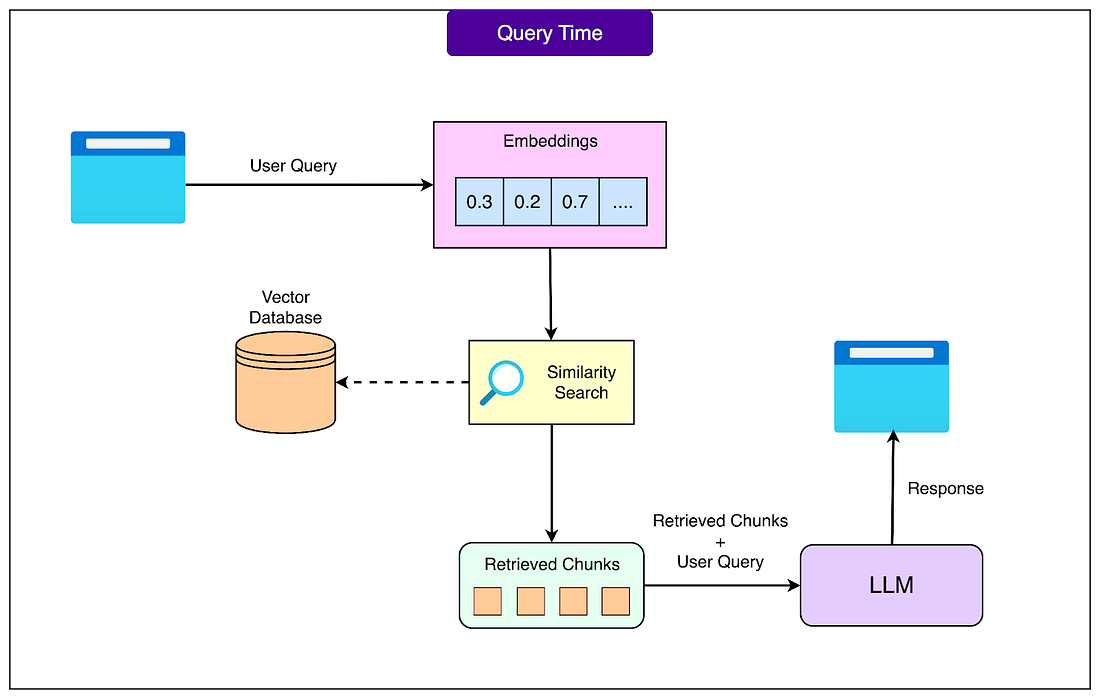
2 - User Query ProcessingWhen a user submits a query, the real-time query processing phase begins. This phase needs to be fast and efficient since users expect quick responses. See the diagram below for a high level view of the process:
Here’s how it works in more detail:
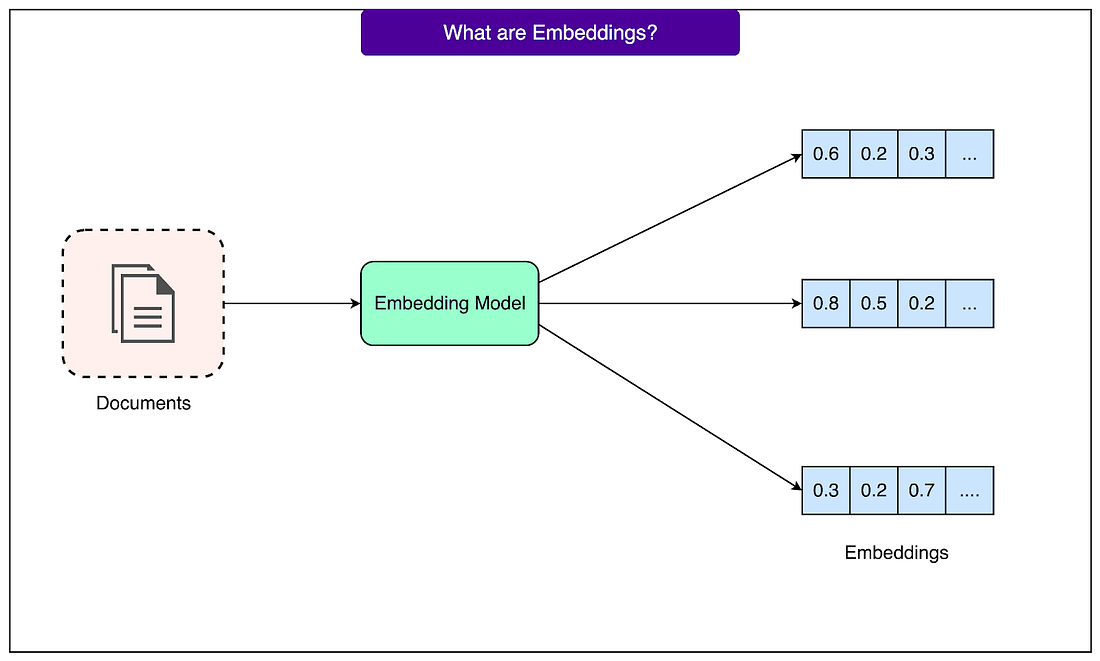
Embeddings - The Heart of RAGThe fundamental challenge in information retrieval is that people express the same ideas in countless different ways. Traditional keyword search, which looks for exact word matches, fails to capture these variations. For example, if the document says "The company permits product returns within 30 days", but a user searches for "How long can I send items back?", the keyword search finds nothing despite the obvious relationship between these texts. Consider the variety of ways someone might ask about a computer problem: "laptop won't start," "computer fails to boot," "system not powering on," or "PC is dead." These phrases share almost no common words, yet they all describe the same issue. A keyword-based system would treat these as completely different queries and miss troubleshooting guides that use different terminology. This vocabulary mismatch problem has plagued information retrieval systems for decades. Embeddings solve this by capturing semantic meaning rather than surface-level word matches. Semantic meaning refers to what the text actually means, not just the specific words used. When text gets converted to embeddings, the resulting numbers represent the concepts and ideas in that text. Sentences about returning products end up with similar number patterns, whether they use words like "return," "refund," "send back," or "exchange." The process of converting text to numbers might seem mysterious, but the principle is straightforward.
See the diagram below:
This numerical representation enables mathematical operations that would be impossible with raw text. Most importantly, we can calculate the distance between two embeddings to measure how similar their meanings are. For example, text about "laptop repairs" and "computer fixes" will have embeddings that are close together in this space, while "laptop repairs" and "cooking recipes" will be far apart. This distance calculation happens through simple mathematics, making it extremely fast even with millions of documents. The reason similar meanings create similar number patterns comes from how embedding models are trained. During training, the model sees millions of examples of text and learns that certain words and phrases appear in similar contexts. For example, words like "doctor" and "physician" show up in similar sentences, get used interchangeably, and relate to the same concepts. The model learns to assign them similar numerical patterns. This learning happens automatically through exposure to vast amounts of text, without anyone explicitly programming these relationships. What makes embeddings particularly fascinating is that we don't fully understand what each dimension represents. When an embedding model outputs 768 numbers for a piece of text, we can't simply say dimension 1 represents "formality" or dimension 547 represents "technical complexity." These dimensions emerge naturally during training as the model figures out what patterns it needs to track to understand language effectively. Some dimensions might loosely correlate with concepts we recognize, like sentiment or topic, but many capture abstract patterns that don't map to any concept we have words for. It's important to understand that embedding models and large language models serve completely different purposes in an RAG system.
This specialization is why RAG systems use two separate models. The embedding model efficiently converts all the documents and queries into vectors, enabling fast similarity search. The LLM then takes the retrieved relevant documents and generates intelligent, contextual responses. Building an RAG SystemWhen building a retrieval-augmented generation (RAG) system, the first step is understanding the requirements clearly. As with most systems, everything begins with the users. Some questions that should be asked are as follows:
Next, we need to look closely at the document landscape. The scale matters in terms of handling a hundred files or hundreds of thousands. Different volumes demand different storage and retrieval strategies. The possible types of content (PDFs, Word docs, Confluence pages, or Notion databases) determine the ingestion and preprocessing pipelines. Equally important is understanding the query patterns by answering questions as follows:
The answer to these questions defines how sophisticated the system must be. Once requirements are clear, we can move to the technology stack. Some of the most popular tools and technologies are as follows:
ConclusionRetrieval-Augmented Generation represents a practical solution to the very real limitations of LLMs in business applications. By combining the power of semantic search through embeddings with the generation capabilities of LLMs, RAG enables AI systems to provide accurate, specific answers based on the organization's own documents and data. Understanding RAG's core concepts helps make informed decisions about whether it's right for a particular use case. If we need AI that can access private company information, provide current updates, cite sources, or maintain strict accuracy, RAG is likely the answer. The two-phase architecture of document preparation and query processing makes it scalable and efficient, while the use of embeddings ensures that users find relevant information regardless of how they phrase their questions. The field of RAG continues evolving rapidly, with improvements in retrieval techniques, better embedding models, and more sophisticated generation strategies. However, the fundamental principles covered here remain constant. SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|

Don't miss a thing Confirm your subscription Hi there, Thanks for subscribing to fitgirl-repacks.site! To get you up and running, please confirm your email address by clicking below. This will set you up with a WordPress.com account you can use to manage your subscription preferences. By clicking "confirm email," you agree to the Terms of Service and have read the Privacy Policy . Confirm email ...
Comments
Post a Comment