Take Control of User Access with WorkOS (Sponsored)
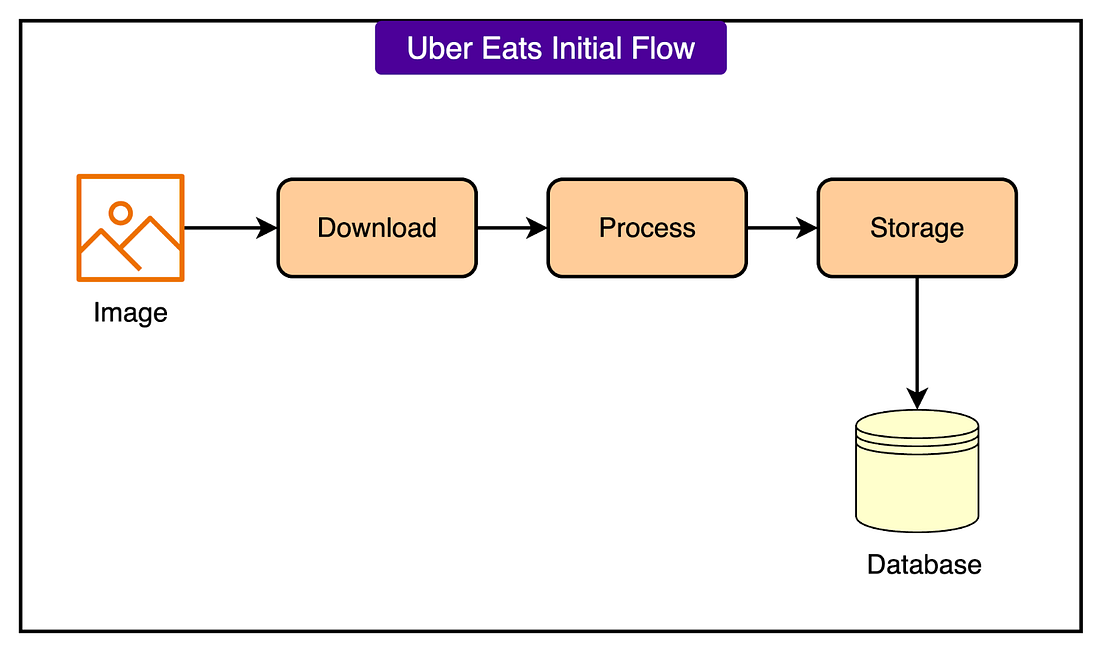
As your app grows, managing “who can do what” becomes complex. Hard-coded roles and scattered permissions slow you down and fail to meet enterprise demands for fine-grained access. Disclaimer: The details in this post have been derived from the official documentation shared online by the Uber Eats Engineering Team. All credit for the technical details goes to the Uber Eats Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. At the scale of Uber Eats, image handling is an operational necessity. The platform manages hundreds of millions of product images, with millions of updates flowing through the system every hour. Every image carries cost: network bandwidth, processing time, storage space, and CDN footprint. As Uber Eats expanded beyond restaurants into groceries, alcohol, and household items, the image pipeline started to strain. For example, a single product, like a can of Coca-Cola, might appear across thousands of storefronts. However, the backend treated each appearance as a fresh upload. There was no concept of shared assets across merchants. Each upload triggered a new download, a new transformation, and a new storage operation, even when the image was identical to one already in the system. The old approach also assumed that a URL change would accompany any image change. It didn’t track content updates if the URL stayed the same. This blocked image refreshes, resulting in awkward workarounds. The engineering goal was clear: reduce unnecessary processing, cut down storage and CDN costs, and reuse existing work wherever possible. In this article, we will look at how Uber achieved this goal of de-duplicating hundreds of millions of images. The Limitations of the Old SystemThe original image pipeline operated on a simple assumption: if the URL is new, the image must be new. If the URL is the same, skip everything. However, there was no mechanism to detect whether two different URLs pointed to the same image. The system treated every incoming URL as unique, even if the underlying image bytes were identical. As a result, the same image, uploaded by different merchants or listed in different contexts, would be downloaded, processed, and stored multiple times. See the diagram below:
Even worse, the system couldn’t detect content changes when the URL stayed constant. If a merchant updated an image without modifying the URL, the system ignored it entirely. There was no validation, no reprocessing, no cache invalidation. This had a few major disadvantages:
The New Image PipelineThe redesigned image pipeline shifts focus from URLs to actual image content. Instead of relying on external signals like URL changes, the system now uses content-addressable caching. Every image is identified by a cryptographic hash of its bytes. If two images are identical, their hashes match, regardless of where they came from or what URL they used. This change enables the system to reuse work across uploads, merchants, and catalog updates without relying on fragile assumptions. The new image service follows three main paths, depending on what it knows about the image:
See the diagram below that shows the three flows:
To support these flows, the system maintains three logical maps as shown in the diagram below:
Each map handles a distinct concern: identifying content, linking processed outputs, and tracking raw assets. The storage details are as follows:
Processing SpecificationsEvery image transformation request includes a processing specification that defines exactly how the image should be handled. This includes:
Together, the image hash and the processing spec form a unique key. If that combination has been processed before, the system can return the result immediately without doing any work. This caching mechanism applies equally to successful transformations and known failures. Errors are treated as first-class results. For example, if an uploaded image is too small to meet the requested resolution, the system logs the failure in the Processed Image Map using the same hash-plus-spec key. The next time that image comes in with the same spec, the system skips the download and transformation and returns the cached error. This avoids repeated failures on the same bad input and prevents wasted compute cycles on requests that are guaranteed to fail. It also makes error reporting faster and more consistent across clients. Handling Image Updates Behind Stable URLsNot every image update comes with a new URL. Merchants often replace the content behind a URL without changing the URL itself. In the old system, this meant updates were silently ignored. The system assumed that a known URL always pointed to the same image, which led to stale or incorrect data being served. To solve this, the new pipeline uses the HTTP Last-Modified header to detect whether an image has changed behind the same URL. During image processing:
See the diagram below:
This approach allows merchants to maintain stable URLs while still delivering updated content. The image pipeline respects those updates without blindly reprocessing every request. It also avoids unnecessary work when nothing has changed. ConclusionThe new content-addressable image pipeline transformed a noisy, redundant workflow into a lean, high-throughput system.
By deduplicating at the content level, the system avoids repeated downloads, transformations, and storage. It handles image updates gracefully, even when merchants reuse URLs. These changes significantly reduced infrastructure demands while improving reliability. Perhaps most impressive is the speed of delivery. The new architecture rolled out in under two months, yet supports one of Uber Eats’ highest-volume data paths. It’s a strong example of how targeted improvements in core systems can unlock broader product velocity, especially when the solution is fast, scalable, and simple to reason about. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|




Don't miss a thing Confirm your subscription Hi there, Thanks for subscribing to fitgirl-repacks.site! To get you up and running, please confirm your email address by clicking below. This will set you up with a WordPress.com account you can use to manage your subscription preferences. By clicking "confirm email," you agree to the Terms of Service and have read the Privacy Policy . Confirm email ...
Comments
Post a Comment