Data Streaming + AI: Shaping the Future Together (Sponsored)
Join us at the Data Streaming + AI Summit on Sept 30, 2025 at the Grand Hyatt at SFO — the most open data streaming conference bringing together leaders from OpenAI, Netflix, Uber, Google, Salesforce, LinkedIn, Blueshift, Confluent, Ververica, StreamNative, and more. Hear keynote insights from Reynold Xin (Co-founder & Chief Architect, Databricks), learn how OpenAI powers AI with real-time streaming, and explore 30+ technical sessions across four tracks. On September 29, level up your skills with Data Streaming Fundamentals Training (for beginners) or dive deeper with the Hands-On Streaming Lakehouse Workshop (advanced, in partnership with AWS). 🎟️ Use code BBG50 for 50% off conference tickets. Language models are no longer limited to text. Today's AI systems can understand images, process audio, and even handle video, but they still need to convert everything into tokens first. Just like how "Hello world!" becomes discrete tokens for text processing, a photograph gets chopped into image patches, and a song becomes a sequence of audio codes. This is Part 2 of the ByteByteGo LLM Tokenization Series. You can view Part 1 here. Each type of media requires completely different tokenization strategies, each with unique trade-offs between quality, efficiency, and semantic understanding.
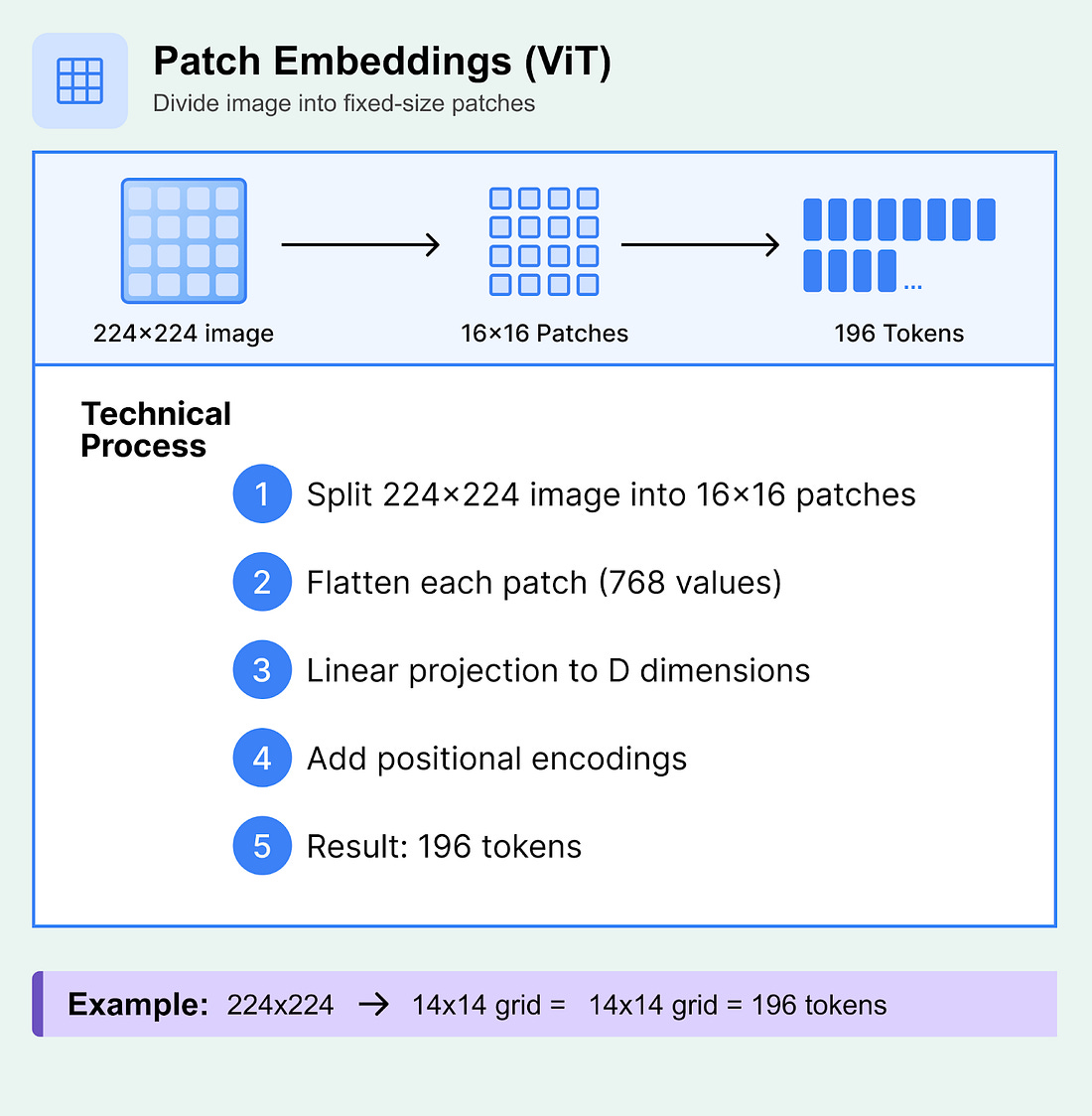
As models extend beyond pure text, multimodal tokenization lets them ingest images, audio, and video alongside natural language. While the core idea of mapping raw input into a discrete sequence remains the same, each modality uses a different strategy. Image TokenizationImage tokenization transforms visual data into discrete tokens that can be processed by LLMs. Unlike text, which naturally exists as discrete symbols, images are continuous pixel arrays that require conversion into token sequences. Main Approaches to Image Tokenization1. Patch Embeddings (Vision Transformer Style)Patch embeddings divide images into fixed-size, non-overlapping “patches”. Each patch is treated as a single token, similar to how words function in text sequences. This allows the image to be processed into understandable units, just like text tokens. Technical Process:
What to know:
Example: A 224×224 image with 16×16 patches yields 196 tokens (14×14 grid).
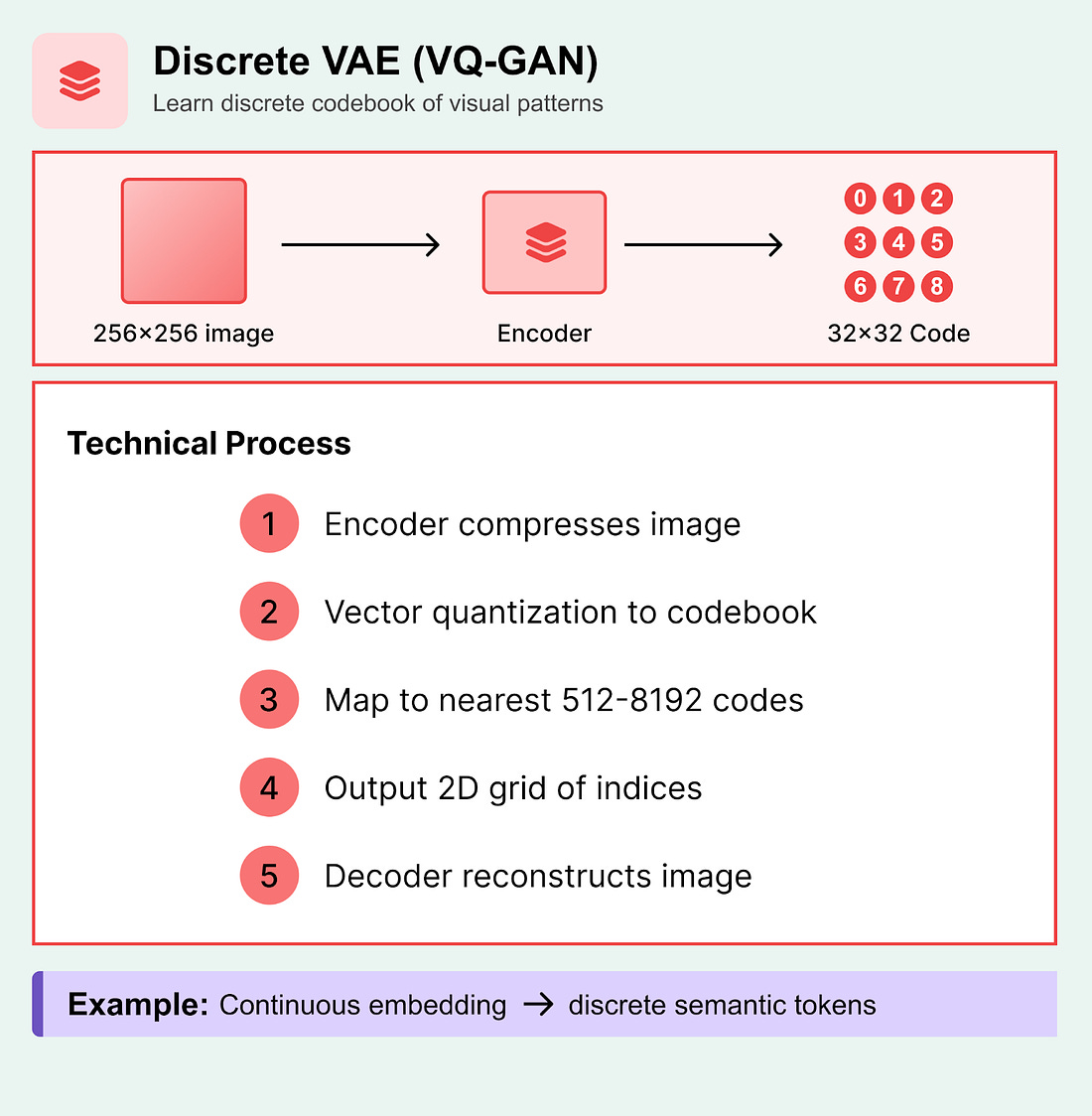
2. Discrete VAE and Vector QuantizationVector quantization is like creating a visual dictionary. It converts values into “buckets” so that AI can pattern match image parts into buckets. Technical Process:
Variants (remove?):
What to know:
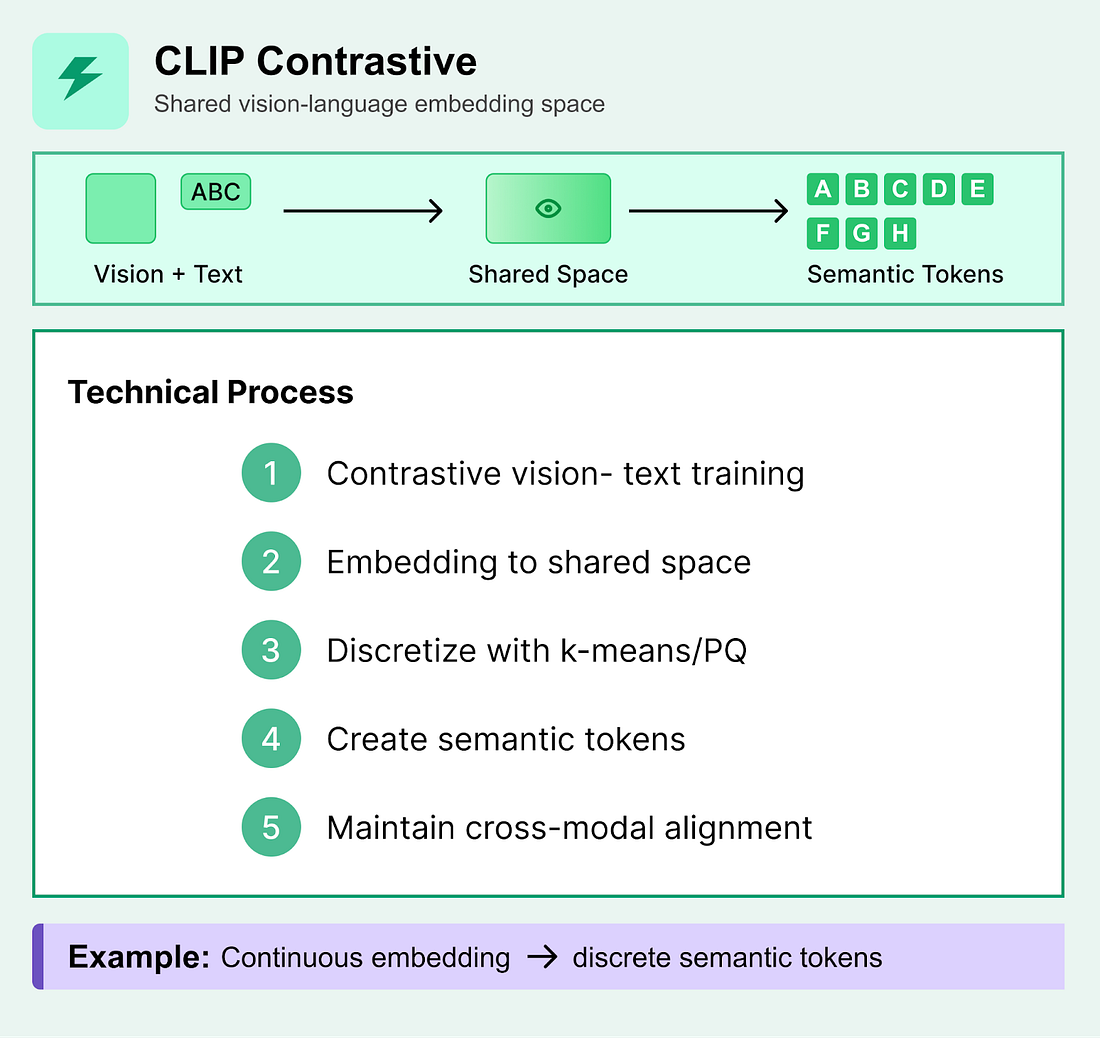
3. CLIP-Style Contrastive EmbeddingsContrastive learning approaches like CLIP create embeddings in a shared vision-language space, which can then be discretized into pseudo-tokens for downstream tasks. Technical Process:
What to know:
Trade-offs to KnowEach tokenization approach has important design decisions to be aware of that impact performance, efficiency, and applicability: Computational Efficiency:
Information Preservation vs Compression:
Audio TokenizationAudio tokenization converts continuous audio waveforms into discrete tokens that can be processed by sequence models. Unlike text or images, audio has unique challenges due to its temporal nature, high sampling rates, and the need to preserve both semantic content and acoustic properties like prosody, timbre, and speaker characteristics. Main Approaches to Audio Tokenization1. Codec Tokens (Neural Audio Codecs)Neural audio codecs like EnCodec and SoundStream compress audio into token sequences while preserving quality. They map audio features to a finite set of learned codes using something called “vector quantization.” Technical Process:
Models:
What to know:
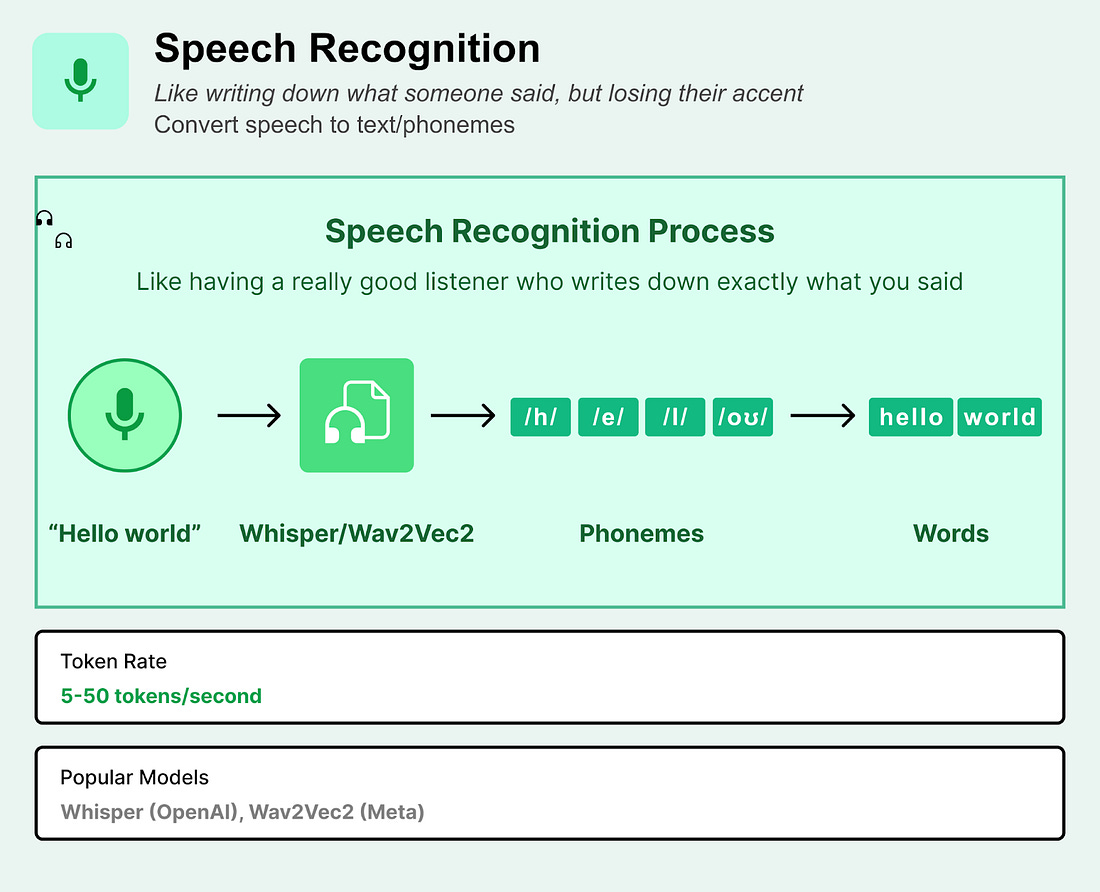
2. Phoneme/Character Tokens (ASR-based)Automatic Speech Recognition converts spoken audio into text representations, creating tokens that capture semantic content but discard acoustic properties. Technical Process:
Token Types:
What to know:
3. Multi-Scale Token Stacks (Hierarchical Representations)Hierarchical approaches use multiple token sequences at different temporal resolutions to capture both global structure and fine-grained details, similar to multi-scale image or video representations. Technical Process:
Implementation Examples:
What to know:
Tradeoffs to RememberTemporal Resolution vs Efficiency:
Semantic vs Acoustic Information:
Quality vs Compression:
Domain Usage:
The best tokenization approach depends on your specific use case: codec tokens for high-quality audio generation, ASR tokens for semantic understanding, and multi-scale approaches when you need both efficiency and quality. Video TokenizationThe most common way that videos are tokenized today is to turn video into video frames and send the video in as a sampling of images, with audio attached. For example, Gemini currently treats video as sequential images interweaved with text/audio (from online sources, so we can link). The Future of TokenizationResearchers are exploring ways to improve tokenization in LLMs:
ConclusionMultimodal tokenization extends the concept of text tokens to images, audio, and video. Images get converted through patch embeddings (splitting into grid squares), vector quantization (learning visual codebooks), or contrastive embeddings (CLIP-style). Audio uses neural codecs (preserving sound quality), ASR transcription (converting to text), or hierarchical approaches (multiple resolution levels). Each method has tradeoffs, and these tokenization choices directly impact what AI systems can understand and generate. ByteByteGo Technical Interview Prep KitLaunching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.
What's included:
SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|





Don't miss a thing Confirm your subscription Hi there, Thanks for subscribing to fitgirl-repacks.site! To get you up and running, please confirm your email address by clicking below. This will set you up with a WordPress.com account you can use to manage your subscription preferences. By clicking "confirm email," you agree to the Terms of Service and have read the Privacy Policy . Confirm email ...
Comments
Post a Comment